

Spark is a data-processing framework that is known to perform processing tasks on large data sets and can distribute data processing tasks across multiple computers. It helps in the quick running of machine learning and has the ability for classification, clustering, collaborative filtering and more. Whether you are a beginner or an intermediate or an expert Spark professional, this guide will help you increase your confidence and knowledge of Spark. The questions below cater to various topics on Spark which will eventually help you know about the most frequently asked questions in the interview. This guide gives you step-by-step explanations for each question that will eventually help you understand the concepts in detail. With Spark interview questions to your rescue, you can be confident about your preparation for the upcoming interview.
This is a frequently asked question in Spark interview questions.
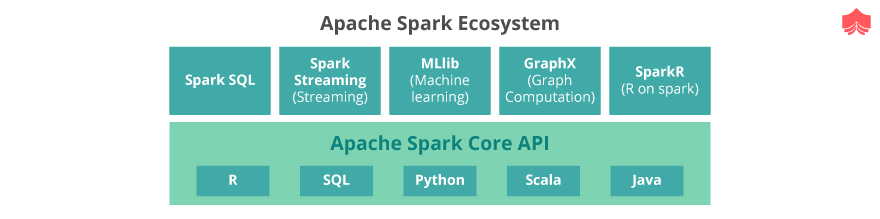
Spark API provides various key features which are very useful for real-time spark processing; most of the features have a good support library along with real-time processing capability.
Below are the key features provided by Spark framework:
Spark core is the heart of spark framework and well support capability for functional programming practice for languages like Java, Scala, and Python; however, most of the new releases come for JVM language first and then later on introduced for python.
Reduce, collection, aggregation API, stream, parallel stream, optional which can easily handle to all the use case where we are dealing volume of data handling.
Bullet points are as follows:
Apparently spark use for data processing framework, however we can also use to perform the data analysis and data science.
Expect to come across this popular question in Apache Spark interview questions.
Spark Streaming supports a micro-batch-oriented stream processing engine. Spark has the capability to allow the data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets,
and can be processed using complex algorithms expressed with high-level functions like map, reduce, join, and window.
Below are the other key benefits which Spark streaming support.
Spark work on batches that receives an input data stream and are divided into micro-batches, which is further processed by the spark engine to generate the final stream of result in the batches.
The below diagram clearly illustrates the workflow of Spark streaming. 
Spark SQL provides programmatic abstraction in the form of data frame and data set which can work the principal of distributed SQL query engine. Spark SQL simplify the interaction to the large amount of data through the dataframe and dataset.
Spark SQL plays a vital role on optimization technique using Catalyst optimizer, Spark SQL also support UDF, built in function and aggregates function.
Master driver is central point and the entry point of the Spark Shell which is supporting this language (Scala, Python, and R). Below is the sequential process, which driver follows to execute the spark job.
The complete process can track by cluster manager user interface. Driver exposes the information about the running spark application through a Web UI at port 4040
A must-know for anyone heading into a Spark interview, this question is frequently asked in Spark interview.
Executors are worker nodes' processes in charge of running individual tasks when Spark jobs get submitted. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task, they send the results to the driver. They also provide in-memory storage for RDDs that are cached by user programs through Block Manager.
Below are the key points on executors:
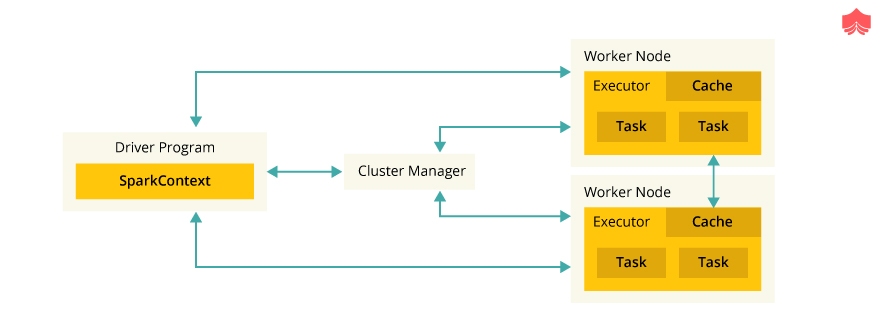
The executor also works as a distributed agent responsible for the execution of tasks. When the job gets launched, the spark triggers the executor, which acts as a worker node responsible for running an individual task which is assigned by spark driver.
Below is the step which spark job follows once job get submitted:
Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. For example, if the node running a partition of a map () operation crashes, Spark will rerun it on another node; and even if the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node and take its result if that finishes.
Resilient distributed dataset (RDD) is a core of Spark framework, which is a fault-tolerant collection of elements that can be operated on in parallel.
Below are the key points on RDD:
We can create the RDD using below approach:
By Referring a dataset:
Val byTextFile = sc.textFile(hdfs:// or s3:// )
By Parallelizing a dataset:
Val byParalizeOperation = sc.paralize( Seq(DataFrame or Dataset), numSlices: Integer)
By converting dataframe to rdd.
Val byDF = df.filter().toRDD
RDDs predominately support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset.
It's no surprise that this one pops up often in Spark interview questions.
Performance
Data Processing
Interactivity
Difficulty
Independent of Hadoop
A common question in interview questions on Spark, don't miss this one.
Below are the core components of Spark Ecosystem.
Spark Core:
Spark Core is the basic engine for large scale parallel and distributed data processing. It performs various important functions like memory management, monitoring jobs, fault-tolerance, job scheduling and interaction with the storage system.
Spark Streaming:
Spark SQL :
Mlib:
GraphX:
One of the most frequently posed Spark interview questions, be ready for it.
Apache Spark has the following key features:
Polyglot
Spark code can be written in Java, Scala, Python, or R. It also provides interactive modes in Scala and Python.
Performance:
Apache Spark is 100 times faster than MapReduce.
Data Formats:
Spark supports multiple data sources such as Parquet, CSV, JSON, Hive, Cassandra and HBase.
Lazy Evaluation :
Spark delays its execution until it is necessary. For transformations, Spark adds them to DAG and executes when the action is performed.
Real-time computation :
Spark computation at real-time has less latency because of its in-memory computation and maximum use of the cluster.
Hadoop Integration :
Spark provides good compatibility with Hadoop. Spark is a potential replacement for MapReduce functions of Hadoop as Spark can run on top of an existing Hadoop cluster using YARN.
Machine Learning:
As Spark has many in-built libraries along with Mlib library, Spark provides Data Engineers and Data Scientists with a powerful unified engine that is fast and easy to use.
Spark application can be run in the following three modes:
Local mode :
This mode runs the entire Spark application on a single machine. It achieves parallelism through threads on that single machine. This is a common way to learn Spark, to test your applications, or experiment iteratively with local development. However, it is not recommended using local mode for running production applications.
Cluster mode :
Cluster mode is the most common way of running Spark Applications in the computer cluster. In cluster mode, the user will submit a pre-compiled JAR, Python script, or R script to a cluster manager. The cluster manager then launches the driver process on one of the worker nodes inside the cluster, in addition to the executor processes which means that the cluster manager is responsible for maintaining all Spark Application– related processes.
Client mode :
Client mode is nearly the same as cluster mode except that the Spark driver remains on the client machine i.e. the machine where that submitted the application. This means that the client machine is responsible for maintaining the Spark driver process, and the cluster manager maintains the executor processes.
A staple in Spark interview questions, be prepared to answer this one.
RDD
RDDs are low-level API and they were the primary API in the Spark 1.x series and are still available in 2.x, but they are not commonly used. However, all spark code you run, whether DataFrames or Datasets, compiles down to an RDD.
RDD stands for Resilient Distributed Dataset. It is a fundamental data structure of Spark and is immutable, partitioned collection of records that can be operated on in parallel.
DataFrame
DataFrames are table-like collections with well-defined rows and columns. Each column must have the same number of rows as all other columns and each column has type information that must be consisted for every row in the collection. To Spark, DataFrame represents immutable lazy evaluated plans that specify what operations to apply to data residing at a location to generate some output. When we perform an action on a DataFrame, we instruct Spark to perform actual transformations and return results.
Dataset
Datasets are a foundational type of Structured APIs. DataFrames are Datasets of type Row.
Datasets are like DataFrames, but Datasets are strictly JVM( Java Virtual Machine) language-specific feature that works with only Java and Scala. We can also say Datasets are ‘ strongly typed immutable collection of objects that are mapped to the relational schema’ in Spark.
RDD :
You should generally use RDD in 3 situations.
DataFrames or Datasets :
All in all, the use of DataFrame/Dataset API is recommendable as easy using and better optimization. Supported by Catalyst and Tungsten, DataFrame/Dataset can reduce your time of optimization, thus you can pay more attention to the data itself.
RDD supports 2 types of operations:
Transformations :
Transformations are functions applied on RDD, resulting in another RDD. It does not execute until an action occurs. Some examples of transformations include a map, filter, and reduceByKey. These transformations apply to each element of RDD and result in another RDD. The filter() creates a new RDD by selecting elements to form current RDD that pass function argument.
Actions:
Actions are the result of RDD/Dataframe transformations or computations. Once an action is performed, the data from RDD moves back to the local machine. An action’s execution is the result of all previously created transformations. Some examples of actions include head, collect, first, take and reduce. collect() is an action which converts RDD to Array of elements. take() action takes all the values from RDD to the local node.
This question is a regular feature in Spark interview, be ready to tackle it.
Spark provides 3 ways to create RDD:
By parallelizing a local Collection :
We can create RDD from the collection. A Collection can be Array, List or Sequence.
val spark = SparkSession.builder().getOrCreate() val sc = spark.sparkContext val collection = Array(1,2,4,6,9) val rdd = sc.parallelize(collection)
From Text files :
We can also create RDD from text file or csv file. val spark = SparkSession.builder().getOrCreate() val sc = spark.sparkContext val rdd = sc.textFile(“path/to/textfile”)
From existing DataFrames or Datasets:
val spark = SparkSession.builder().getOrCreate() val df = spark.range(10) val rdd = df.rdd
Lineage graph:
It is the graph of how all the parent RDD’s are connected to the derived RDD’s. It represents how each RDD is depended on others and how transformations are applied to each RDD.
For example-
val rdd1 = rdd.map()
Here result keeps a reference of the RDD data, that’s a lineage. This RDD lineage is used to recompute the data if there are faults while computing.
DAG:
DAG stands for Directed Acyclic Graph. DAG is a collection of all the RDD and the corresponding transformations on them. DAG will be created when the user creates RDD and applies transformations on them. When action is performed DAG will be given to the DAG scheduler which divides DAG into stages. DAG can help with fault tolerance.
Difference between lineage graph and DAG :
Lineage graph deals with RDD’s so it is applicable till transformations, whereas DAG shows different stages of Spark job. It shows the complex task i.e. transformations + Actions.
Transformations are the core of how you express your business logic using Spark. There are two types of transformations in Spark.:
Narrow Transformations :
Transformations consist of narrow transformations are those for which each input partition will contribute to only one output partition.
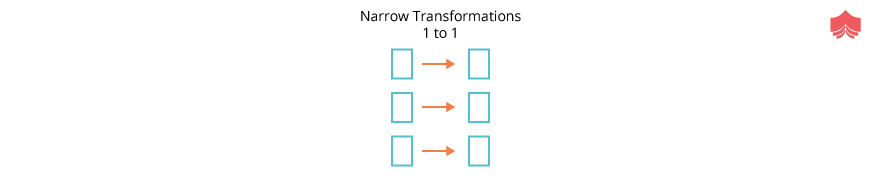
Some of the narrow transformations are map(), flatMap(), filter(), mapPartition(),union().
All the above transformations contribute only one partition at most one partition as shown in the above diagram.
Example :
val rdd1 = rdd.map( x => x+1 )
Above business logic just executes in each partition without need of other partition data.
Wide Transformations :
Wide transformations will have many input partitions contributes to many output partitions. We often hear this referred to as a shuffle where the Spark will exchange partitions across the cluster.
-.jpg)
Some of the wide transformations are distinct(), reduceByKey(), groupByKey(), join(), repartition(), coalesce(). All these transformations contribute many input partitions to many output partitions.
Example :
val rdd1 = rdd.distint()
Above transformation can’t produce accurate results if it executes in one partition, many partitions data is needed to get the distinct values from RDD.
Expect to come across these popular Spark scenario-based interview questions.
Mahout is a machine learning library for Hadoop; similarly, MLlib is a Spark library. MetLib provides different algorithms that algorithms scale out on the cluster for data processing. Most data scientists use this MLlib library which has the following advantages:
Ease of Use
MLlib can be usable in multiple wide programming languages like Java, Scala, Python, and R. MLlib also fits into Spark's APIs and interoperates with NumPy in Python and R libraries. You can use any Hadoop data source. HDFS, HBase, or local files to make it easy to plug into Hadoop workflows.
Performance
As we already discussed in the above questions, MLib is 100x faster than MapReduce, and it has high-quality algorithms. Spark excels at iterative computation, enabling MLlib to run fast. At the same time, we care about algorithmic performance: MLlib contains high-quality algorithms that leverage iteration and can yield better results than the one-pass approximations sometimes used on MapReduce.
Runs Everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud, against diverse data sources. You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
It's no surprise that this one pops up often in Spark performance tuning interview questions.
One common type of supervised learning is classification. Classification is the act of training an algorithm to predict a dependent variable that is categorical (belonging to a discrete, finite set of values). The most common case is binary classification, where our resulting model will make a prediction that a given item belongs to one of two groups.
A canonical example is classifying email spam. Using a set of historical emails that are organized into groups of spam emails and not spam emails, we train an algorithm to analyze the words in, and any number of properties of, the historical emails and make predictions about them. Once we are satisfied with the algorithm’s performance, we use that model to make predictions about future emails the model has never seen before.
When we classify items into more than just two categories, we call this multiclass classification. For example, we may have four different categories of an email (as opposed to the two categories in the previous paragraph): spam, personal, work-related, and other.
A common question in Spark interview questions, don't miss this one.
GraphFrames is currently available as a Spark package, an external package that you need to load when you start up your Spark application, but it may be merged into the core of Spark in the future.
For the most part, there should be little difference in performance between the two (except for a huge user experience improvement in GraphFrames). There is some small overhead when using GraphFrames, but for the most part, it tries to call down to GraphX where appropriate; and for most, the user experience gains greatly outweigh this minor overhead.
A graph is nothing but just a logical representation of data. Graph theory provides numerous algorithms for analyzing data in this format, and GraphFrames allows us to leverage many algorithms out of the box.
Page Rank
One of the most prolific graph algorithms is PageRank. Larry Page, a co-founder of Google, created PageRank as a research project for how to rank web pages.
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites. In very short form PageRank is a ‘vote’ by all other pages on the internet web and about how important a page is. If a link to a page count as a vote of support of a web page. If there is no link then there is no support.
Caching or Persistence is an optimization technique involving saving the results date result to disk or memory.
An RDD can be involved in multiple transformations/actions. Each such transformation will require the same RDD to be evaluated multiple times. This is both time and memory consuming. It can be easily avoided by caching or persisting the RDD. The difference between cache() and persist() in Spark is that in the case of former, storage level is Memory Only while later provides a host of other storage levels.
There are five different storage levels in Spark:
Deploy mode determines where the driver program will run on the Spark cluster.
There are two types of deploy modes in Spark:
This mode can be chosen for running small jobs.
One of the most frequently posed Spark interview questions, be ready for it.
Coalesce in Spark provides a way to reduce the number of partitions in an RDD or data frame. It works on existing partitions instead of creating new partitions, thereby reducing the amount of data that is shuffled.
A good use for coalesce is when data in RDD has been filtered out. As a result of filtering, some of the partitions in RDD may now be empty or have fewer data. Coalesce will help reduce the number of partitions, thereby helping optimize any further operations on the RDD. Note that coalesce cannot be used to increase the number of partitions.
Consider the following example:
The data has been read from a CSV file into an RDD having four partitions:
Filter operation is applied on the RDD, which removes all multiples of 10. The resultant RDD will look like below:
As can be seen, the RDD has some empty partitions or ones having very little data. Hence it makes sense to reduce the number of partitions. Using coalesce we can achieve the same. The resultant RDD when coalesce(2) has been applied will look like:
Repartition, on the other hand, can be used to increase or decrease the number of partitions in RDD. Repartition works by doing a full shuffle of data and creating new partitions. As full data shuffle is involved, it is an expensive operation.
Shuffling is the process of redistributing data across partitions that may cause data movement across executors.
By default, shuffling doesn’t change the number of partitions, but their content. There are many different operations that require shuffling of data, for instance, join between two tables or byKey operations such as GroupByKey or ReduceByKey.
Shuffling is a costly operation as it involves the movement of data across executors and care must be taken to minimize it. This can be done using optimized grouping operation such as using reduceByKey instead of groupByKey. While groupByKey shuffles all the data, reduceByKey shuffles only the results of aggregations of each partition and hence is more optimized than groupByKey.
When joining two tables opt to use the same partitioner on both the tables. This would store values having the same key in same chunk/partition. This way Spark would not have to go through the entire second table for each partition of the first table hence reducing shuffling of data.
Another optimization is to use broadcast join when joining a large table with a smaller one. This would broadcast a smaller table's data to all the executors hence reducing shuffling of data.
A staple in Spark interview questions, be prepared to answer this one.
Spark supports several cluster managers. They are:
DAGScheduler is the scheduling layer of Apache Spark that implements stage-oriented scheduling. It transforms a logical execution plan into the DAGScheduler which is the scheduling layer of Apache Spark that implements stage-oriented scheduling. SparkContext hands over a logical plan to DAGScheduler that it in turn translates to a set of stages that are submitted as TaskSets for execution.
TaskScheduler is responsible for submitting tasks for execution in a Spark application. TaskScheduler tracks the executors in a Spark application using executorHeartbeatReceived and executor Lost methods that are to inform about active and lost executors, respectively. Spark comes with the following custom TaskSchedulers: TaskSchedulerImpl — the default TaskScheduler (that the following two YARN-specific TaskSchedulers extend). YarnScheduler for Spark on YARN in client deploy mode. YarnClusterScheduler for Spark on YARN in cluster deploy mode.
BackendScheduler is a pluggable interface to support various cluster managers, cluster managers differ by their custom task scheduling modes and resource offers mechanisms Spark abstracts the differences in BackendScheduler contract.
Responsible for the translation of spark user code into actual spark jobs executed on the cluster.
Spark driver prepares the context and declares the operations on the data using RDD transformations and actions. Driver submits the serialized RDD graph to the master, where master creates tasks out of it and submits them to the workers for execution. Executor is a distributed agent responsible for the execution of tasks.
Below is the key point for the reference:
Spark driver coordinates the different job stages, where the tasks are actually executed. They should have the resources and network connectivity required to execute the operations requested on the RDDs.
Lazy evaluation in spark works to instantiate the variable when its really required for instance like when spark do the transformation, till this time it’s not computed, however when we applied the action than its compute the data. Spark delays its evaluation till it is necessary.
Eg: lazy val lazydata = 10
This question is a regular feature in Spark interview questions for experienced, be ready to tackle it.
| Feature Criteria | Apache Spark | Hadoop |
|---|---|---|
| Speed | 100 times faster than Hadoop | Slower than the Spark |
| Processing | Support both Real-time & Batch processing | Batch processing only |
| Difficulty | Easy because of high level modules | Tough to learn |
| Recovery | Allows recovery of partitions | Fault-tolerant |
| Interactivity | Has interactive modes | No interactive mode except Pig & Hive |
GraphX is a part of Spark framework, which use for graph and graph based parallel processing, GraphX extends the Spark RDD by introducing a new Graph abstraction: a directed multigraph with properties attached to each vertex and edge. To support graph computation.
GraphX in spark are immutable, distributed, and fault-tolerant. Changes to the values or structure of the graph are accomplished by producing a new graph with the desired changes.
MLib is a scalable machine library which comes as a bundle of Spark framework. Spark provide a high-quality well tested algorithms to performs data science operation.
Below are the key points:
Code Snippet: data = spark.read.format("libsvm").load("hdfs://...")model = KMeans(k=10).fit(data)
MLlib utilize the linear algebra package Breeze, which depends on netlib-java for optimized numerical processing. If native libraries1 are not available at runtime, you will see a warning message and a pure JVM implementation will be used instead.
| Dataframe | Dataset |
|---|---|
| Dataframe is structured into named and column and provides a same behaviour which is in table in RDBMS | Dataset is distributed collection of data, which provide the benefits of both RDD and dataframe |
| Dataframe doesn’t require schema or meta information about the and does not process strict type checking. | To create dataset we need to provide the schema information about the record and follows strict type checking. |
| Dataframe doesn’t allow lambda function | Dataset support support lambda function. |
| Dataframe doesn’t comes with optimize engine | Dataset comes with Spark SQL optimize engine called Catalyst optimizer |
| Dataframe doesn’t support any encoding technique at runtime | Dataset comes with encoder technique, which provide technique to convert JVM object into the dataset. |
| Incompatible with domain object, once dataframe created, we can’t regenerate the domain object. | Regeneration of domain object is possible, because dataset need the schema information before creating the |
| Dataframe doesn’t support the compile time safety. | Dataset maintain the schema information, if schema is incorrect than its generate the exception at compile time. |
| Once dataframe get created, we can’t perform any RDD operation on it. | Dataset leverage to use RDD operation as well along with sql query processor. |
It's no surprise that this one pops up often in Spark scala interview questions.
Cache and persist methods are optimization techniques in Spark that save the result of RDD evaluation. By using cache and persist, we can save the intermediate results so that we can use them further if required.
We can make RDD persist in memory(which can be in-memory or dist )using cache() and persist() methods.
If we make RDDs cache() method, it stores all the RDD data in-memory.
We use persist() method in RDD to save all the RDD in memory as well. But the difference is the cache() stores RDD in the system/clusters in-memory, but persist() method can use various storage levels to store the RDD. By default, persist() uses MEMORY_ONLY, it is equal to cache() method.
Below are the various levels of persist().
Need for persistence :
In Spark, we often use the same RDD’s multiple times. When we repeatedly process the same RDD multiple times, it requires time to evaluate each time. This task can be time and memory-consuming, especially iterative algorithms that require data multiple times. To solve the problem of repeated computation, we require a persistence technique.
A common question in Spark interview questions, don't miss this one.
In addition to RDD abstraction, the second kind of Low-level API is shared variables in Spark. Spark has two types of distributed shared variables:
These variables can be used in User Defined Functions(UDFs).
Broadcast Variables
Broadcast variables are the variables to share an immutable value efficiently around the cluster without encapsulating that variable in a function closure. The normal way to use a variable in our driver node inside your tasks is to simply reference it in your function closures (e.g., in a map operation), but this can be inefficient, especially for large variables such as a lookup table or a machine learning model. The reason for this is that when you use a variable in a closure, it must be deserialized on the worker nodes many times.
Moreover, if you use the same variable in multiple Spark actions and jobs, it will be re-sent to the workers with every job instead of once. This is where broadcast variables come in. Broadcast variables are shared, immutable variables that are cached on every machine in the cluster instead of serialized with every single task. The canonical use case is to pass around a large lookup table that fits in memory on the executors and use that in a function.
Accumulators
Spark’s second type of shared variables is a way of updating a value inside of a variety of transformations and propagating that value to the driver node in an efficient and fault-tolerant way. Accumulators provide a mutable variable that a Spark cluster can safely update on a per-row basis. We can use these for debugging purposes or to create low-level aggregation.
We can use them to implement counters or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types. For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will be applied only once, meaning that restarted tasks will not update the value. In transformations, we should be aware that each task’s update can be applied more than once if tasks or job stages are re-executed.
Accumulators do not change the lazy evaluation model of Spar. Accumulator updates are not guaranteed to be executed when made within a lazy transformation like map().
Accumulators can be both named and unnamed. Named accumulators will display their running results in the Spark UI, whereas unnamed ones will not.
Spark Streaming is real-time processing of streaming data. Through Spark streaming, we achieve fault tolerant processing of live data stream. The input data can be from any source. For example, like Kafka, Flume, kinesis, twitter or HDFS/S3. Spark includes two streaming API’s:
DStream API :
Spark’s DStream API has been used broadly for stream processing since its first release in 2012. Many companies use and operate Spark Streaming at scale in production today due to its high-level API interface and simple exactly once semantics. Interactions with RDD code, such as joins with static data, are also natively supported in Spark Streaming. Operating Spark streaming is not much more difficult than operating a normal Spark cluster. However, the DStreams API has some limitations.
Structured Stream API:
Structured Streaming is a higher-level streaming API built from the ground up on Spark’s Structured APIs. It is available in all the environments where structured processing runs, including Scala, Java, Python, R, and SQL. Like DStreams, it is a declarative API based on high-level operations, but by building on the structured data model, Structured Streaming can perform more types of optimizations automatically. However, unlike DStreams, Structured Streaming has native support for event time data.
More fundamentally, beyond simplifying stream processing, Structured Streaming is also designed to make it easy to build end-to-end continuous applications using Apache Spark that combine streaming, batch, and interactive queries. Structured Streaming will automatically update the result of this computation in an incremental fashion as data arrives.
A streaming application must operate 24/7 and hence must be resilient to failures unrelated to the application logic like system failures, JVM crashes, etc.. For this to be possible, Spark Streaming needs to checkpoint enough information to a fault- tolerant storage system such that it can recover from failures. There are two types of data that are checkpointed.
To summarize, metadata checkpointing is primarily needed for recovery from driver failures, whereas data or RDD checkpointing is necessary even for basic functioning if stateful transformations are used.
When to enable Checkpointing :
Checkpointing must be enabled for applications with any of the following requirements:
Note that simple streaming applications without the stateful transformations can be run without enabling checkpointing. The recovery from driver failures will also be partial in that case (some received but unprocessed data may be lost). This is often acceptable and many run Spark Streaming applications in this way. Support for non-Hadoop environments is expected to improve in the future.
One of the most frequently posed Spark interview questions for experienced, be ready for it.
Checkpointing can be enabled by setting a directory in a fault-tolerant, reliable file system like HDFS, S3, etc., to which the checkpoint information will be saved. This is done by using streamingContext.checkpoint(checkpointDirectory). This will allow you to use the aforementioned stateful transformations.
Additionally, if you want to make the application recover from driver failures, you should use checkpointing functionality in your streaming application to have the following behavior:
def createStreamingContext():StreamingContext ={
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams ...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, createStreamingContext _)If the checkpointDirectory exists, then the context will be recreated from the checkpoint data. If the directory does not exist (i.e., running for the first time), then the function createStreamingContext will be called to create a new context and set up the DStreams.
There are three modes supported by Structured Streaming. Let’s look at each of them:
Append mode
Append mode is the default behavior and the simplest to understand. When new rows are added to the result table, they will be output to the sink based on the trigger (explained next) that you specify. This mode ensures that each row is output once (and only once), assuming that you have a fault-tolerant sink. When you use append mode with event-time and watermarks, only the final results will output to the sink.
Complete mode
The complete model will output the entire state of the result table to your output sink. This is useful when we are working with some stateful data for which all rows are expected to change over time or the sink you are writing does not support row-level updates. Think of it as the state of a stream at the time the previous batch had run.
Update mode
Update mode is complete mode except that only the rows that are different from the previous write are written out to the sink. Naturally, your sink must support row-level updates to support this mode. If the query doesn’t contain aggregations, this is equivalent to append mode.
Event Time :
At a higher level, in stream-processing systems, there are effectively two relevant times for each event: the time at which it actually occurred (event time) and the time that it was processed or reached the stream-processing system (processing time).
Event time:
Event time is the time that is embedded in the data itself. It is most often, though not required to
be, the time that an event actually occurs. This is important to use because it provides a more
robust way of comparing events against one another. The challenge here is that event data can be late or out of order. This means that the stream processing system must be able to handle out-of-order or late data.
Processing time:
Processing time is the time at which the stream-processing system actually receives data. This is usually less important than event time because when it is processed, is largely an implementation detail. This can not ever be out of order because it is a property of the streaming system at a certain time.
Stateful Processing :
Stateful processing is only necessary when you need to use or update intermediate information (state) over longer periods of time (in either a micro-batch or a record-at-a-time approach). This can happen when you are using event time or when you are performing aggregation on a key, whether that involves event time or not.
For the most part, when we are performing stateful operations, Spark handles all of this complexity for us. For example, when you specify a grouping, Structured Streaming maintains and updates the information for you. You simply specify the logic. When performing a stateful operation, Spark stores the intermediate information in a state store. Spark’s current state store implementation is an in-memory state store that is made fault tolerant by storing intermediate state to the checkpoint directory.
A staple in Spark interview questions and answers, be prepared to answer this one.
There are many optimization techniques that we can perform to help Spark job run faster.
We will list some of them. Please note that these can be applied when your code requires improvement in performance based on the functionality which you are implementing.
It enables the computers or the machines to make data-driven decisions rather than being explicitly programmed for carrying out a certain task. These programs or algorithms are designed in a way that they learn and improve over time when are exposed to new data.
Machine Learning algorithm is trained using a training data set to create a model. When new input data is introduced to the ML algorithm, it makes a prediction based on the model.
The prediction is evaluated for accuracy and if the accuracy is acceptable, the Machine Learning algorithm is deployed. If the accuracy is not acceptable, the Machine Learning algorithm is trained again and again with an augmented training data set.
For example :
Online Shopping
While doing online shopping, when we are checking for a product, we can notice the recommendations for a product similar to what you are looking for, and we can also notice “the person bought this product also bought this” combination of products. How are they doing this recommendation? This is machine learning.
Insurance policy
Sometimes you are getting calls from insurance/third party company for asking you to take insurance, What do you think, do they call everyone? No, they call only a few selected customers who they think will purchase their product. How do they select? This is target marketing and can be applied using Clustering. This is machine learning.
Machine learning is sub categorized into 3 types:
Supervised Learning :
Supervised Learning is the one, where you can consider the learning is guided by a supervisor. Let’s say we have a dataset which acts as a supervisor and its role is to train the model or the machine. Once the model gets trained it can start making a prediction or decision when new data is given to it. It is including classification and regression, where the goal is to predict a label for each data point based on various features.
Unsupervised Learning :
The model learns through observation and finds structures in the data. Once the model is given a dataset, it automatically finds patterns and relationships in the dataset by creating clusters in it. What it cannot do is add labels to the cluster, like it cannot say this a group of apples or mangoes, but it will separate all the apples from mangoes.
Suppose we presented images of apples, bananas, and mangoes to the model, so what it does, based on some patterns and relationships it creates clusters and divides the dataset into those clusters. Now if a new data is fed to the model, it adds it to one of the created clusters. It is also including clustering, anomaly detection, and topic modeling, where the goal is to discover structure in the data.
Reinforcement Learning :
It is the ability of an agent to interact with the environment and find out what is the best outcome. It follows the concept of hit and trial method. The agent is rewarded or penalized with a point for a correct or a wrong answer and based on the positive reward points gained the model trains itself. And again, once trained it gets ready to predict the new data presented to it.
There are many uses for Classification. We will discuss some of them:
Predicting disease
A doctor or hospital might have a historical dataset of behavioral and physiological attributes of a set of patients. They could use this dataset to train a model on this historical data (and evaluate its success and ethical implications before applying it) and then leverage it to predict whether a patient has heart disease or not. This is an example of binary classification (healthy heart, unhealthy heart) or multiclass classification (healthy heart, or one of several different diseases).
Classifying images
There are several applications from companies like Apple, Google, or Facebook that can
predict who is in each photo by running a classification model that has been trained on
historical images of people in your past photos. Another common use case is to classify images or label the objects in images.
Predicting customer churn
A more business-oriented use case might be predicting customer churn—that is, which customers are likely to stop using a service. You can do this by training a binary classifier on past customers that have churned (and not churned) and using it to try and predict whether current customers will churn.
Buy or won’t buy
Companies often want to predict whether visitors of their website will purchase a given product. They might use information about users browsing pattern or attributes such as location in order to drive this prediction.
Some of the use cases for unsupervised learning include:
Anomaly detection
Given some standard event type often occurring over time, we might want to report when a nonstandard type of event occurs. For example, a security officer might want to receive notifications when a strange object (think vehicle, skater, or bicyclist) is observed on a pathway.
User segmentation
Given a set of user’s behaviors, we might want to better understand what attributes certain users share with other users. For instance, a gaming company might cluster users based on properties like the number of hours played in a given game. The algorithm might reveal that casual players have very different behavior than hardcore gamers, for example, and allow the company to offer different recommendations or rewards to each player.
Topic modeling
Given a set of documents, we might analyze the different words contained therein to see if there is some underlying relationship between them. For example, given several web pages on data analytics, a topic modeling algorithm can cluster them into pages about machine learning, SQL, streaming, and so on based on groups of words that are more common in one topic than in others.
Intuitively, it is easy to see how segmenting customers could help a platform cater better to each set of users. However, it may be hard to discover whether this set of user segments is “correct”. For this reason, it can be difficult to determine whether a particular model is good or not.
This question is a regular feature in Spark interview questions and answers for experienced, be ready to tackle it.
Graphs are data structures composed of nodes, or vertices, which are arbitrary objects and edges that define relationships between these nodes. Graph analytics is the process of analyzing these relationships. An example graph might be your friend group. In the context of graph analytics, each vertex or node would represent a person, and each edge would represent a relationship.
Graphs are a natural way of describing relationships and many different problem sets, and Spark provides several ways of working in this analytics paradigm. Some business use cases could be detecting credit card fraud, motif finding, determining the importance of papers in bibliographic networks (i.e., which papers are most referenced), and ranking web pages, as Google famously used the PageRank algorithm to do.
Spark has long contained an RDD-based library for performing graph processing: GraphX. This provided a very low-level interface that was extremely powerful but, just like RDDs, wasn’t easy to use or optimize. GraphX remains a core part of Spark. Companies continue to build production applications on top of it, and it still sees some minor feature development. The GraphX API is well documented simply because it hasn’t changed much since its creation.
However, some of the developers of Spark (including some of the original authors of GraphX) have recently created a next-generation graph analytics library on Spark: GraphFrames. GraphFrames extends GraphX to provide a DataFrame API and support for Spark’s different language bindings so that users of Python can take advantage of the scalability of the tool.
Below are some of the use cases for Graph Analytics:
Fraud prediction
Capital, one uses Spark’s graph analytics capabilities to better understand fraud networks. By using historical fraudulent information (like phone numbers, addresses, or names) they discover fraudulent credit requests or transactions. For instance, any user accounts within two hops of a fraudulent phone number might be considered suspicious.
Anomaly detection
By looking at how networks of individuals connect with one another, outliers and anomalies can be flagged for manual analysis. For instance, if typically, in our data each vertex has ten edges associated with it and a given vertex only has one edge, that might be worth investigating as something strange.
Classification
Given some facts about certain vertices in a network, you can classify other vertices according to their connection to the original node. For instance, if a certain individual is labeled as an influencer in a social network, we could classify other individuals with similar network structures as influencers.
Recommendation
Google’s original web recommendation algorithm, PageRank, is a graph algorithm that analyses website relationships in order to rank the importance of web pages. For example, a web page that has a lot of links to it is ranked as more important than one with no links to it.
This is a frequently asked question in Spark performance tuning interview questions.
Structured Streaming provides a fast, fault-tolerant and exactly-once stream processing while allowing users to use DataFrame/Dataset API to express streaming aggregations, event time windows, etc.
The computation is executed on the same Spark SQL engine. You express your streaming computation the same way you would express a batch computation using DataFrame/Dataset. Spark SQL engine takes care of running it incrementally and updating the final result as and when streaming data keeps arriving.
Output modes define the way data is written to result from the table. There are three different output modes in Spark Structured Streaming.
Checkpointing is defined as the process of truncating the RDD lineage graph and storing it to a fault-tolerant file system such as HDFS.
By default, Spark maintains a history of all transformations you apply to a DataFrame or RDD. While this enables Spark to be fault-tolerant, it also results in a performance hit an entire set of transformations on RDD/Dataframe needs to be recomputed in case fault occurs during application execution. This can be avoided with the use of checkpoints. Checkpointing truncates the RDD lineage graph and saves it to HDFS. Spark then keeps track of only the transformations that have been applied after checkpointing.
Checkpointing helps Spark achieve exactly once, fault-tolerant guarantee. It uses checkpointing and write-ahead logs to record the offset range of data processed in each trigger. In case of a failure, data can be replayed using checkpointed offsets after a failure.
Persisting an RDD stores it to Disk or Memory. However, Spark remembers the RDD lineage though it doesn’t call it. After the job run is complete, the cache is cleared.
With Checkpointing, RDD is stored to HDFS and the lineage gets deleted. When the job run is completed, the checkpoint file is not deleted.
On heap memory refers to objects stored on JVM heap and bound by JVM Garbage Collection.
Off-heap memory objects are stored outside of Java heap via serialization, managed by the application and not bound by garbage collection. This method is heavily used by Spark as it avoids frequent GC and tight control over the lifecycle of objects. However, the logic for memory allocation and release needs to be custom written by the application as is the case with Spark.
Since version 1.6, Spark has been following the Unified Memory model wherein both Storage memory and Execution memory share a memory area and both can occupy each other’s free area.
By default, Spark uses On-heap memory only. Its size can be configured using parameter ‘spark.executor.memory’ at the time of submitting the job. On heap memory area can be divided into four parts:
Off-heap memory can be enabled by setting the parameter ‘spark.memory.offHeap.enabled’ to true. This memory area consists of only two parts – Storage memory and Execution memory. When Off-heap memory is enabled, an executor will use both On heap and Off-heap memory.
A common question in Spark interview, don't miss this one.
Broadcast variables provide a way to keep a read-only variable cached on each executor from the driver program. Broadcast variables allow for the efficient sharing of large data sets intended as reference data for workers. If regular variables had to be used for this purpose instead, then the variable would have to be shipped to each executor for every transformation and action. One of the common use cases for a broadcast variable is to store and share a lookup table in a join operation.
When Spark ships a regular variable to executors, they become local to the executor, and its updated value is not relayed back to the driver. Accumulator variables are a special type of variable wherein updates to the variable on executor nodes are relayed back to the driver. They can be used for associative or commutative operations. One of the common use cases is to analyze transaction logs. However, when using accumulators following needs to be considered:
To be on the safe side, accumulators should be used inside actions only.
It's no surprise that this one pops up often in Spark interview questions for experienced.
When a Spark job is submitted, each worker node launches an executor. The data is read from the source into RDDs or Data Frames, which can be considered a sort of big arrays with multiple partitions. Each executor can launch one or more tasks, with each task mapping to a partition, thereby increasing parallelism.
However, in case the data is skewed i.e. some of the partitions contain much larger data compared to others, then tasks operating on larger partitions can take much longer to complete than those which operate on smaller partitions.
Data skewness can arise due to multiple reasons e.g. say source contains user data for various countries. If the data is partitioned based on country, then a partition for a country having a larger population will have more data leading to data skewness. A better way to handle this situation is to partition data based on a key which results in a more balanced spreading of data.
Another way to handle this problem is to use repartition. Spark repartition does a full shuffle of data in RDD and creates new partitions with data distributed evenly. Since the data is more evenly spread now, tasks operating on partitions will take an equal amount of time to process now. Keep in mind that repartitioning your data is a fairly expensive operation.
Yet another option is to cache the RDD or Dataframe before heavy operations as caching helps optimize performance to a great extent.
circumstances. Other than that, there are libraries for SQL, graph computation, machine learning, and stream processing. The programming languages that Spark support are Python, Java, R and Scala. Data scientists and application developers incorporate Spark in their applications to query, analyse and transform data at scale. Tasks that are most frequently associated with Spark include SQL batch jobs, machine learning tasks, etc.
Professionals can opt for a career as a Spark Developer, Big Data developer, Big Data Engineer and related profiles. According to indeed.com, the average salary of "big data spark developer" ranges from approximately $105,767 per year for a Data Warehouse Engineer to $133,184 per year for Data Engineer.
There are many companies who use Apache Spark. According to iDatalabs, most of the companies that are using Apache Kafka are found in the United States, particularly in the industry of Computer Software. Mostly, these companies have 50-200 employees with revenue of 1M-10M dollars. Hortonworks Inc, DataStax, Inc., and Databricks Inc are some of the top industry majors.
Are you wondering how to crack the Spark Interview and what could be the probable Spark Interview Questions asked? Then you should realize that every interview is different and the scope of jobs differ in every organisation. Keeping this in mind, we have designed the most common Apache Spark Interview Questions and Answers to help you crack your interview successfully.
We have compiled the most frequently asked Apache Spark Interview Questions with Answers for both experienced as well as freshers. These Spark SQL interview questions will surely help you to get through your desired Spark Interview.
After going through these Spark interview questions and answers you will be able to confidently face an interview and will be prepared to answer your interviewer in the best manner. Spark coding interview questions here are suggested by the experts.
Prepare well and in time!All the best!
Get a 1:1 Mentorship call with our Career Advisor
Book free session